Publication List
: Lifelong Learning; : Robustness; : Data-Model Efficiency; : Distributed Learning
- [MSU-UM] CyclicReflex: Improving Reasoning Models via Cyclical Reflection Token Scheduling, Chongyu Fan, Yihua Zhang, Jinghan Jia, Alfred Hero, Sijia Liu, ICLR 2026, [].
- [UM] Universal Training of Neural Networks to Achieve Bayes Optimal Classification Accuracy, Mohammadreza Tavasoli Naeini, Ali Bereyhi, Morteza Noshad, Ben Liang, Alfred Hero, ICASSP 2025 (Best Student Paper Award), [].
- [MSU] LLM Unlearning Reveals a Stronger-Than-Expected Coreset Effect in Current Benchmarks, Soumyadeep Pal, Changsheng Wang, James Diffenderfer, Bhavya Kailkhura, Sijia Liu, under review, [].
- [MSU] Towards LLM Unlearning Resilient to Relearning Attacks: A Sharpness-Aware Minimization Perspective and Beyond, Chongyu Fan, Jinghan Jia, Yihua Zhang, Abhay Ramakrishna, Mingyi Hong, Sijia Liu, arXiv 2502.05374, under review, [, ].
- [MSU] Simplicity Prevails: Rethinking Negative Preference Optimization for LLM Unlearning, Chongyu Fan, Jiancheng Liu, Lunjia Lin, Jinghan Jia, Ruiqi Zhang, Song Mei, Sijia Liu, arXiv 2410.07163, under review, [].
- [MSU] WAGLE: Strategic Weight Attribution for Effective and Modular Unlearning in Large Language Models, Jinghan Jia, Jiancheng Liu, Yihua Zhang, Parikshit Ram, Nathalie Baracaldo, Sijia Liu, NeurIPS 2024, [, ].
- [MSU-UM] Challenging Forgets: Unveiling the Worst-Case Forget Sets in Machine Unlearning, Chongyu Fan, Jiancheng Liu, Alfred Hero, Sijia Liu, ECCV 2024, [, ].
- [UM] Multi-Trigger-Key: Towards Multi-Task Privacy Preserving In Deep Learning, Ren Wang, Zhe Zhu, Alfred Hero, IEEE Access, Feb 2024, [].
- [MSU] Model Sparsity Can Simplify Machine Unlearning, Jinghan Jia, Jiancheng Liu, Parikshit Ram, Yuguang Yao, Gaowen Liu, Yang Liu, Pranay Sharma, Sijia Liu, NeurIPS 2023 (Spotlight), [].
- [MSU] Selectivity Drives Productivity: Efficient Dataset Pruning for Enhanced Transfer Learning, Yihua Zhang, Yimeng Zhang, Aochuan Chen, Jinghan Jia, Jiancheng Liu, Gaowen Liu, Mingyi Hong, Shiyu Chang, Sijia Liu, NeurIPS 2023, [].
- [UM] Minimum-Risk Recalibration of Classifiers, Zeyu Sun, Dogyoon Song, Alfred Hero, NeurIPS 2023 (Spotlight), [].
- [MSU-UM] Robustness-Preserving Lifelong Learning Via Dataset Condensation, Jinghan Jia, Yihua Zhang, Dogyoon Song, Sijia Liu, Alfred Hero, ICASSP 2023, [, ].
- [UM] Securely Aggregated Coded Matrix Inversion, Neo Charalambides, Mert Pilanci, Alfred Hero, Journal of Selected Areas of Information Theory, Special Issue Dedicated to the Memory of Alex Vardi, Oct 2023, [].
Project Highlights
NeurIPS 2024
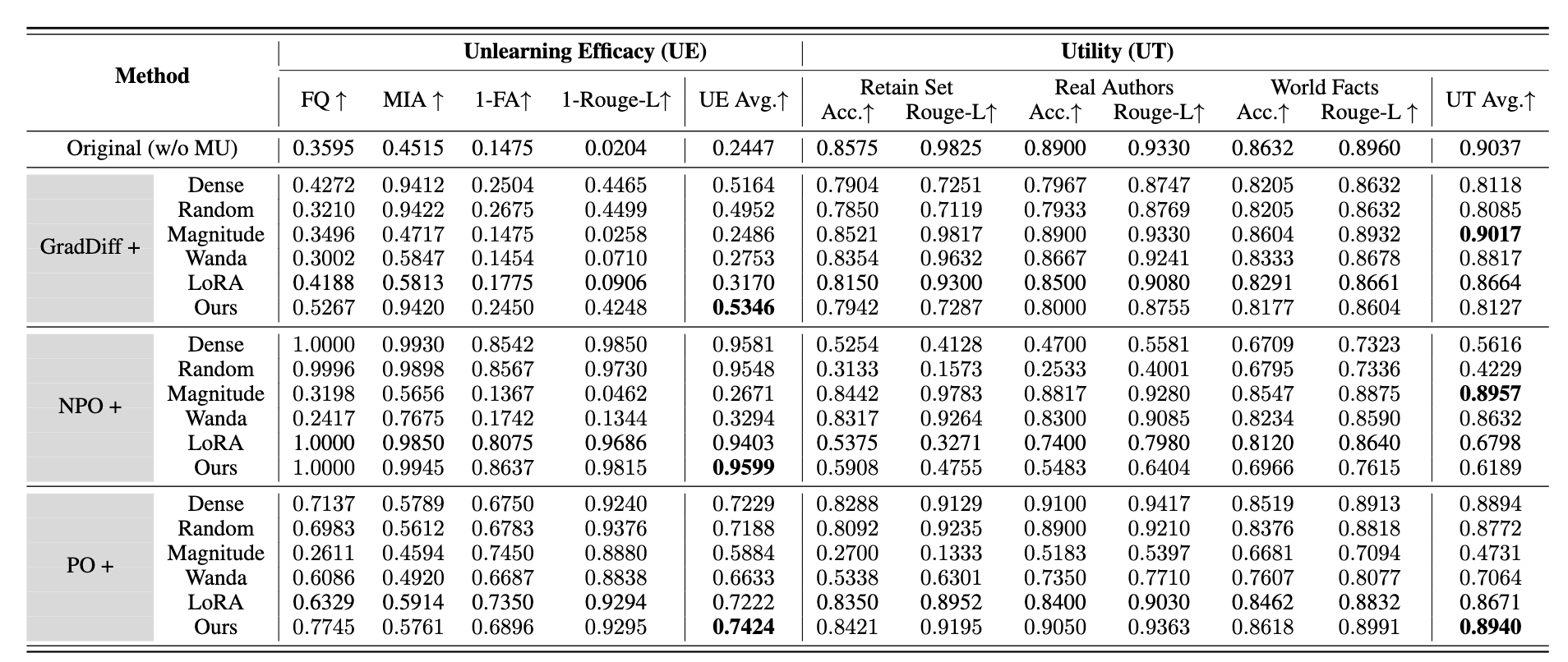
WAGLE: Strategic Weight Attribution for Effective and Modular Unlearning in Large Language Models
Jinghan Jia, Jiancheng Liu, Yihua Zhang, Parikshit Ram, Nathalie Baracaldo, Sijia Liu
The MSU-IBM team proposes WAGLE, a principled framework for LLM unlearning that leverages strategic weight attribution to pinpoint and erase the influence of unwanted data. By aligning the "influence" of weights with data to forget or retain, WAGLE enhances the effectiveness of a wide range of unlearning methods—such as gradient difference and negative preference optimization—across multiple benchmarks including TOFU and WMDP. It is the first method to explicitly connect weight attribution with unlearning efficacy, providing strong forgetting while preserving original task performance.
ECCV 2024
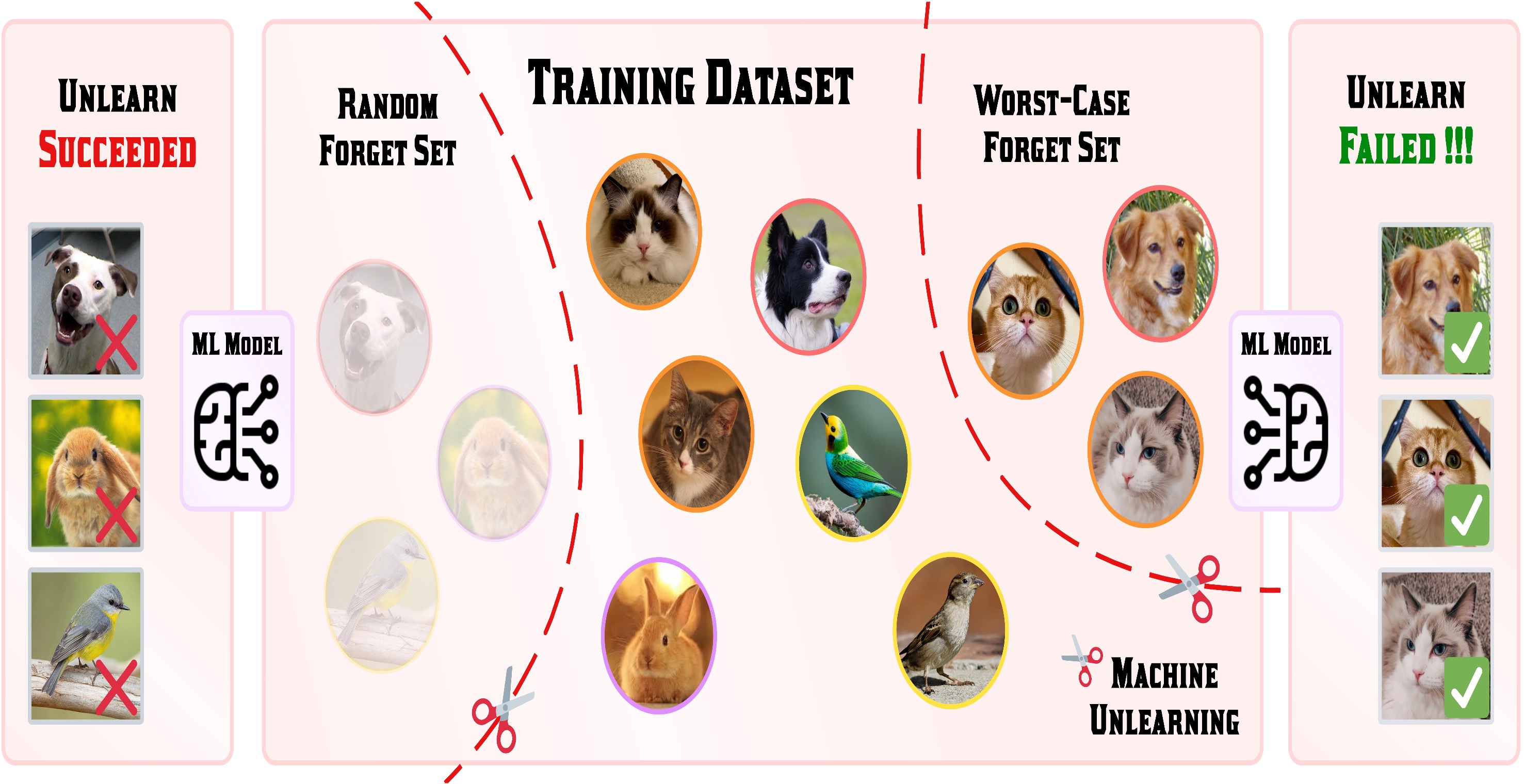
Challenging Forgets: Unveiling the Worst-Case Forget Sets in Machine Unlearning
Chongyu Fan, Jiancheng Liu, Alfred Hero, Sijia Liu
The MSU-UM team uses bi-level optimization to investigate the worst-case evaluation for "forgetting" (or "machine unlearning"). Their research demonstrates the relationship between the difficulty of machine unlearning and the data. Additionally, their work on machine unlearning is connected to "curriculum learning".
NeurIPS 2023 [Spotlight]
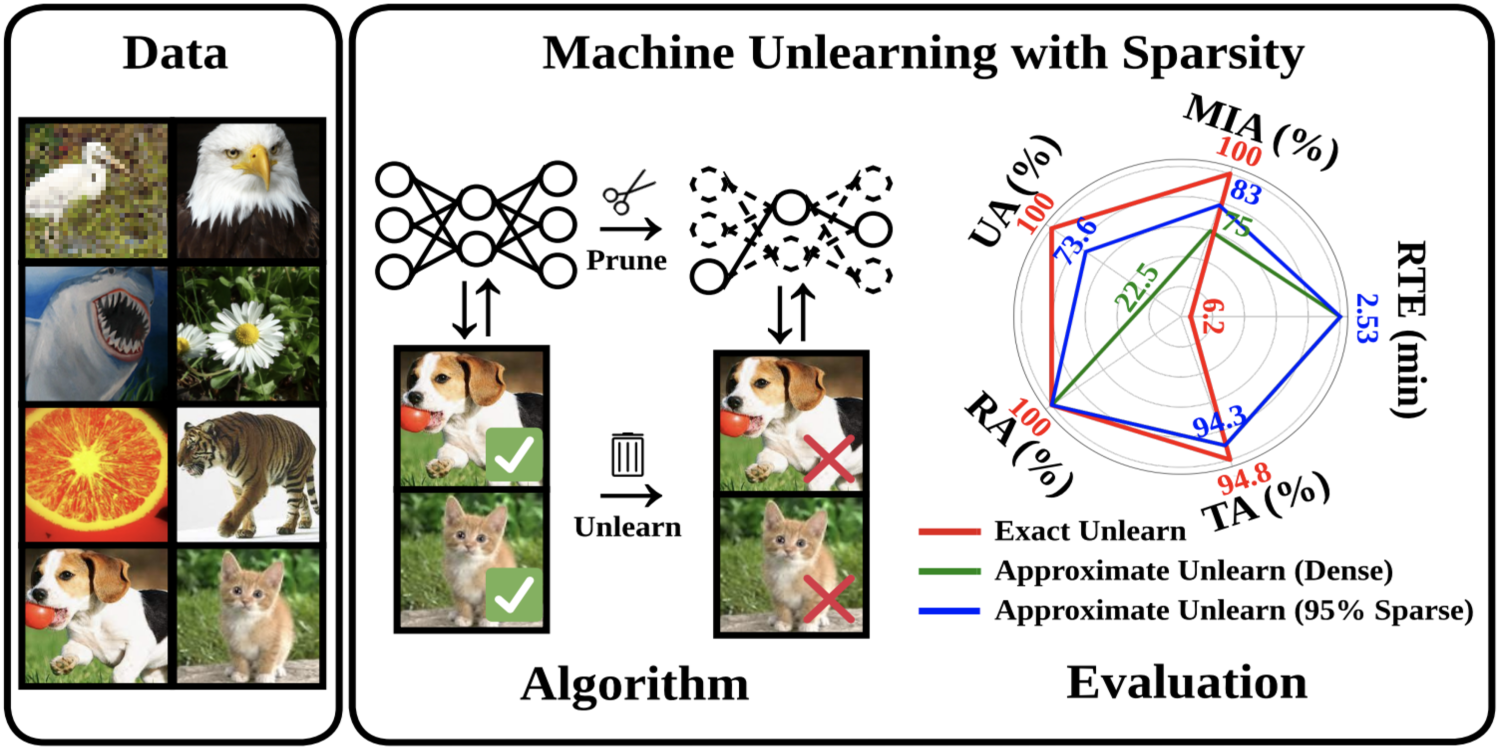
Model Sparsity Can Simplify Machine Unlearning
Jinghan Jia, Jiancheng Liu, Parikshit Ram, Yuguang Yao, Gaowen Liu, Yang Liu, Pranay Sharma, Sijia Liu
The MSU team investigates the concept of “forgetting” (or “machine unlearning”) in ML training, specifically in the context of “targeted forgetting” to respond to data deletion tasks from users. This research demonstrates, both theoretically and practically, that “model sparsity” can effectively facilitate unlearning for better outcomes. The research on machine unlearning also links to “continual learning”.
NeurIPS 2023 [Spotlight]
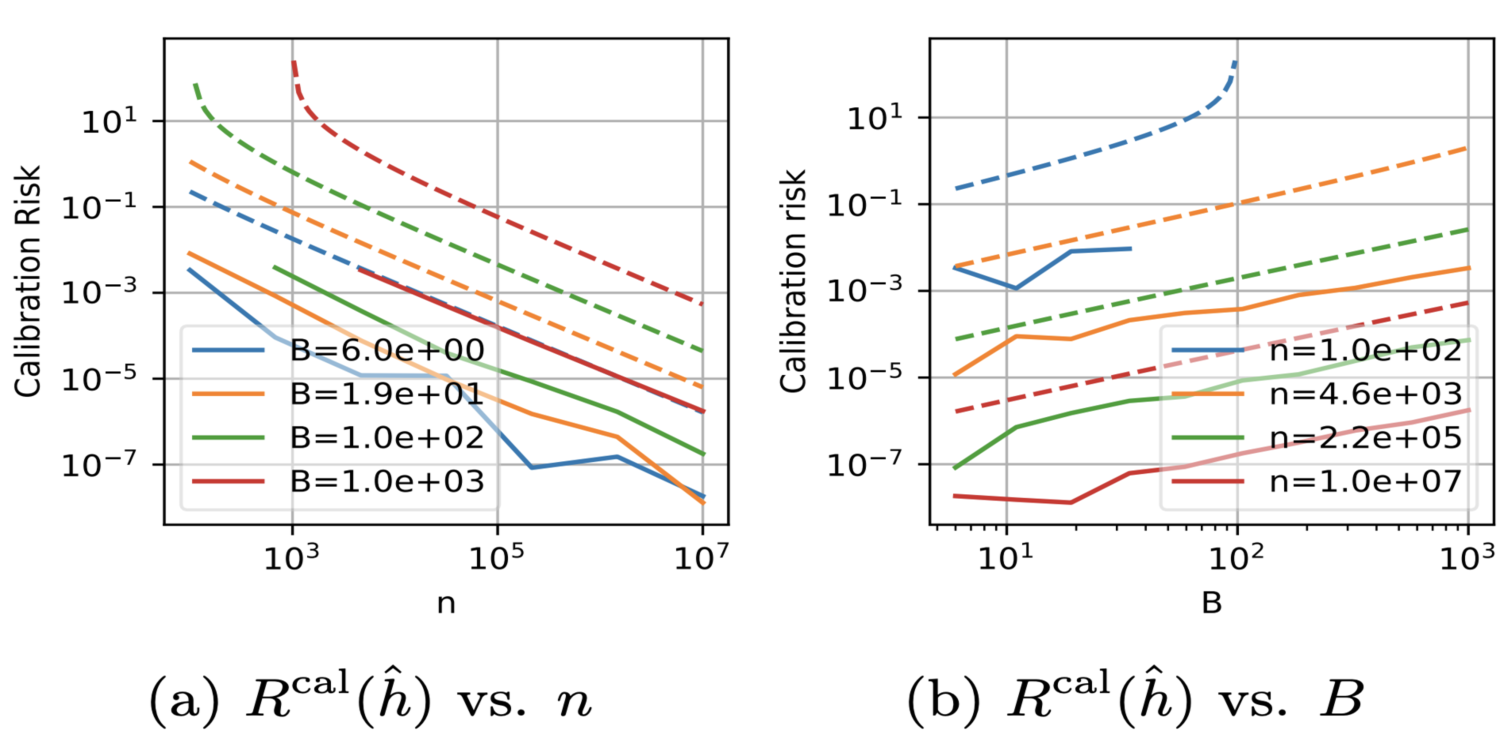
Minimum-Risk Recalibration of Classifiers
Zeyu Sun, Dogyoon Song, Alfred Hero
The UM team investigates the realm of transfer learning, particularly when recalibrating a pre-trained ML model to new local data. This work provides valuable insights, demonstrating the advantages of calibrating a pre-trained model compared to training from scratch on all data, and has significant relevance in scenarios like federated learning, where models are shared among agents, one of whom possesses a large pretrained model.
NeurIPS 2023
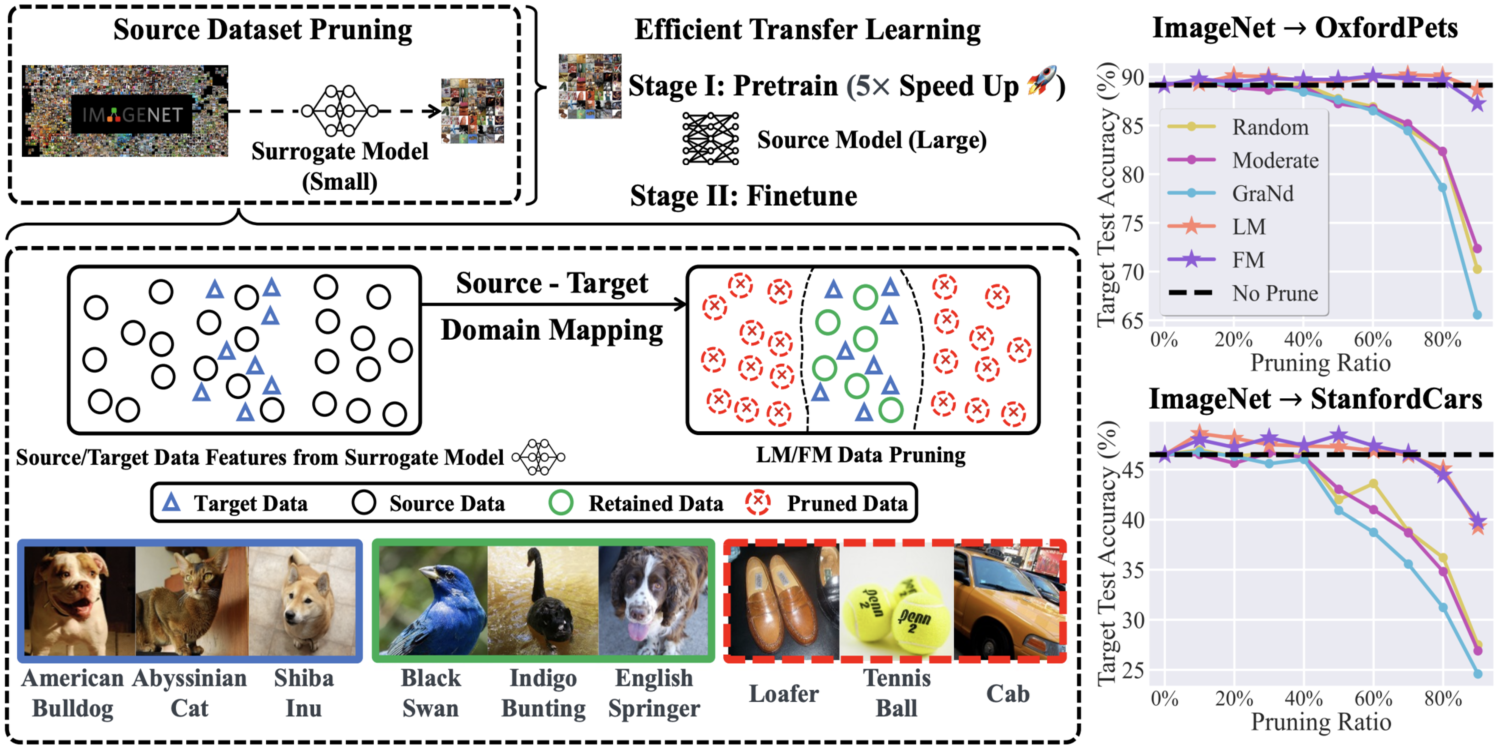
Selectivity Drives Productivity: Efficient Dataset Pruning for Enhanced Transfer Learning
Yihua Zhang, Yimeng Zhang, Aochuan Chen, Jinghan Jia, Jiancheng Liu, Gaowen Liu, Mingyi Hong, Shiyu Chang, Sijia Liu
The MSU team explores the efficient pruning of large-scale source datasets to facilitate more efficient source/foundational model training without compromising transfer learning performance on downstream tasks.
ICASSP 2023
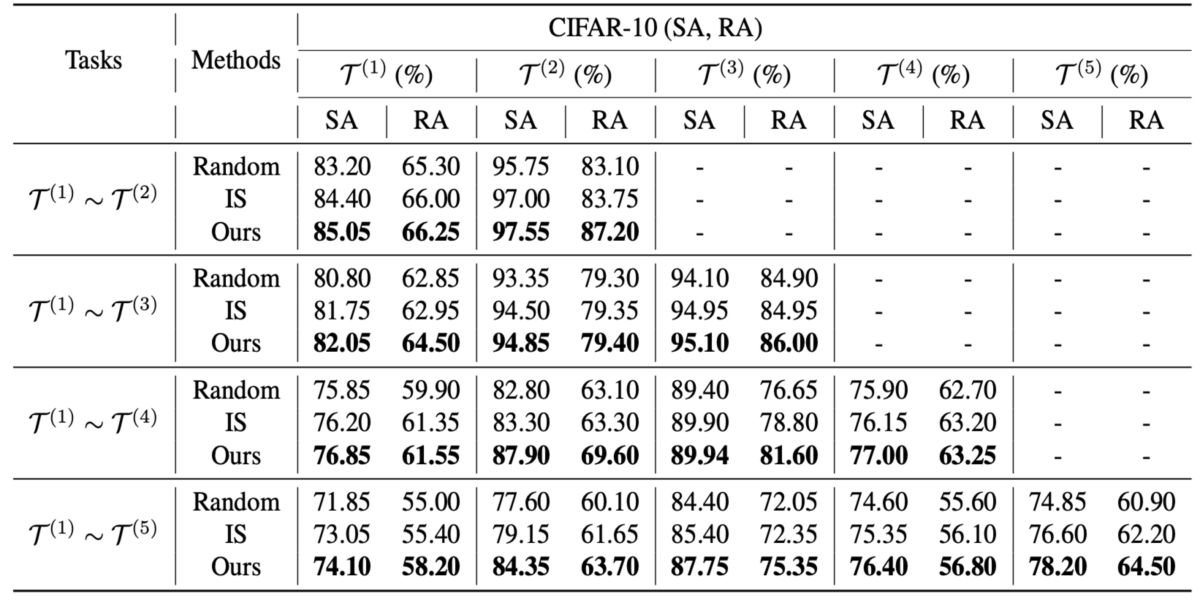
Robustness-Preserving Lifelong Learning Via Dataset Condensation
Jinghan Jia, Yihua Zhang, Dogyoon Song, Sijia Liu, Alfred Hero
The MSU-UM team proposes a new memory-replay LL strategy that leverages modern bi-level optimization techniques to determine the "coreset" of the current data (i.e., a small amount of data to be memorized) for ease of preserving adversarial robustness over time.